Публикации |
 |
2023 г. – новый этап практического применения CXL, статья |
|
VMware сдвигает акцент в проекте Capitola на CXL, статья |
|
Dell Validated Design for Analytics — Data Lakehouse: интегрированное хранилище данных, статья |
|
OCP Global Summit: решения для Computational Storage и компонуемых масштабируемых архитектур, статья |
|
Samsung CXL MemoryySemantic SSD: 20M IOPs, статья |
|
UCIe – открытый протокол для взаимосвязи чиплетов и построения дезагрегированных инфраструктур, статья |
|
Omni-Path Express – открытый интерконнект для экзафлопных HPC/AI-систем, статья |
|
GigaIO: CDI_решение на базе AMD для высшего образования, статья |
|
Энергоэффективные ЦОД на примерах решений Supermicro, Lenovo, Iceotope, Meta, статья |
|
От хранилищ данных и “озер данных” к open data lakehouse и фабрике данных, статья |
|
EuroHPC JU развивает НРС-экосистему на базе RISC-V, статья |
|
LightOS™ 2.2 – программно-определяемое составное блочное NVMe/TCP хранилище, статья |
|
End-to-end 64G FC NAFA, статья |
|
Computational Storage, статья |
|
Технология KIOXIA Software-Enabled Flash™, статья |
|
Pavilion: 200 млн IOPS на стойку, статья |
|
CXL 2.0: инновации в операциях Load/Store вводаавывода, статья |
|
Тестирование референсной архитектуры Weka AI на базе NVIDIA DGX A100, статья |
|
Fujitsu ETERNUS CS8000 – единая масштабируемая платформа для резервного копирования и архивирования, статья |
|
SmartNIC – новый уровень инфраструктурной обработки, статья |
|
Ethernet SSD, JBOF, EBOF и дезагрегированные хранилища, статья |
|
Compute, Memory и Storage, статья |
|
Lenovo: CXL – будущее серверов с многоуровневой памятью
, статья |
|
Liqid: компонуемые дезагрегированные инфраструктуры для HPC и AI, статья |
|
Intel® Agilex™ FPGA, статья |
|
Weka для AI-трансформации, статья |
|
Cloudera Data Platform – “лучшее из двух миров”, статья |
|
Fujitsu ETERNUS DSP - разработано для будущего, статья |
|
Технологии охлаждения для следующего поколения HPC-решений, статья |
|
Что такое современный HBA?, статья |
|
Fugaku– самый быстрый суперкомпьютер в мире, статья |
|
НРС – эпоха революционных изменений, статья |
|
Новое поколение СХД Fujitsu ETERNUS, статья |
|
Зональное хранение данных, статья |
|
За пределами суперкомпьютеров, статья |
|
Применение Intel® Optane™ DC и Intel® FPGA PAC, статья |
|
Адаптивные HPC/AI-архитектуры для экзаскейл-эры, статья |
|
DAOS: СХД для HPC/BigData/AI приложений в эру экзаскейл_вычислений, статья |
|
IPsec в пост-квантовую эру, статья |
|
LiCO: оркестрация гибридныхНРС/AI/BigData_инфраструктур, статья |
| |
Обзоры |
 |
Все обзоры в Storage News |
| |
Тематические публикации |
|
Flash-память |
|
Облачные вычисления/сервисы |
|
Специализ. СХД для BI-хранилищ, аналитика "больших данных", интеграция данных |
|
Современные СХД |
|
Информационная безопасность (ИБ), борьба с мошенничеством |
|
Рынки |
|
RAS-возможности серверов Lenovo ThinkSystem на базе процессоров Intel Xeon
21, март 2023 —
https://lenovopress.lenovo.com/lp1711-ras-features-of-the-lenovo-thinksystem-intel-servers
Надежность , доступность и удобство обслуживания (RAS) серверов являются критически важными вопросами для современных корпоративных ИТ - отделов , которые предоставляют критически важные приложения и услуги , а сбои в доставке приложений могут быть чрезвычайно дорогостоящими в час простоя системы . Масштабируемые процессоры Intel Xeon, работающие на серверах ThinkSystem, по - прежнему лидируют в отрасли в отношении функций RAS. В этой статье объясняется важность функций RAS на сервере и приводится список ключевых функций RAS на новейших серверах ThinkSystem, которые Lenovo предлагает клиентам , стремящимся свести к минимуму время простоя в своем центре обработки данных .
Введение
Такие приложения , как база данных , планирование ресурсов предприятия (ERP), управление ресурсами клиентов (CRM) и бизнес - аналитика (BI), должны быть доступны 24 часа в сутки 7 дней в неделю на широкой территории или по всему миру . Кроме того , вероятность таких сбоев статистически увеличивается с размером серверов , данных и памяти , необходимых для этих развертываний .
Хотя кластеризация и виртуализация могут помочь удовлетворить требования доступности , они не являются подходящими решениями для очень больших баз данных , бизнес - аналитики и высокопроизводительных транзакционных систем . Сбой , затрагивающий одно основное бизнес - приложение , может стоить сотни тысяч или даже миллионы долларов в час . Все это приводит к необходимости масштабируемых и высокоустойчивых серверов , которые хорошо подходят для критически важных бизнес - приложений и крупномасштабной консолидации .
Всегда включен
Время - деньги . Даже несколько минут простоя могут привести к значительным затратам и остановке внутренних бизнес - операций . Простои также могут отрицательно сказаться на отношениях компании с клиентами , поставщиками и партнерами . Надежность или ее отсутствие могут нанести ущерб репутации компании и привести к потере бизнеса .
Рост числа новых приложений выдвинул обработку баз данных и бизнес - аналитику на первое место в списке серверных рабочих нагрузок . Эти рабочие нагрузки требуют постоянной доступности корпоративных платформ , на которых они выполняются .
« Всегда включен » стал глобальным требованием и влияет на многие аспекты нашей жизни :
- Максимальная производительность . Производителям необходимо поддерживать свою производственную линию в рабочем состоянии . Время простоя системы не должно прерывать ее .
- Контролируйте доступ — компании , занимающиеся безопасностью объектов , предотвращают внешние угрозы организациям . Время простоя приложения безопасности не должно быть внутренней угрозой .
- Защищайте прибыль . У розничных продавцов есть цели по продажам , которые нужно выполнять изо дня в день . Простои системы транзакций не должны мешать .
- Защищайте жизни . Службы экстренного реагирования принимают меры в чрезвычайных ситуациях 24 часа в сутки , 7 дней в неделю , 365 дней в неделю . Простои приложений не должны быть одной из них .
- Обеспечьте качественное обслуживание и конфиденциальность . Учреждениям здравоохранения необходимо постоянно иметь доступ к информации о пациентах и ??соответствовать требованиям HIPPA. Время простоя системы не должно ставить под угрозу ни один из них .
- Обработка транзакций . Организации , предоставляющие финансовые услуги , обрабатывают тысячи транзакций в секунду . Простой процессинговой системы просто невозможен
Сервер RAS определен
RAS по отношению к серверам определяется следующим образом :
Надежность — сокращение среднего времени между сбоями оборудования и обеспечение целостности данных . Целостность данных обеспечивается за счет обнаружения и исправления ошибок или , если они не поддаются исправлению , локализации ошибок .
- Обнаружение ошибок и самовосстановление
- Сводит к минимуму возможность простоя
- Постоянно исправлять результаты
Доступность — относится к бесперебойной работе системы и приложений даже при наличии неисправимых ошибок .
- Сокращение частоты и продолжительности простоев
- Самодиагностика : работа с неисправными компонентами или « самовосстановление »
- Никогда не останавливается и не замедляется
Удобство обслуживания — означает , что систему можно обслуживать без прерывания работы . Эта возможность требует как продуманного дизайна платформы , так и инновационного управления системами .
- Избегайте повторных сбоев благодаря точной диагностике
- Параллельный ремонт элементов с более высокой частотой отказов
- Легко ремонтировать и обновлять
Отраслевая стоимость простоя
90% выживших компаний говорят , что стоимость 1 часа простоя превышает 300 тысяч долларов .
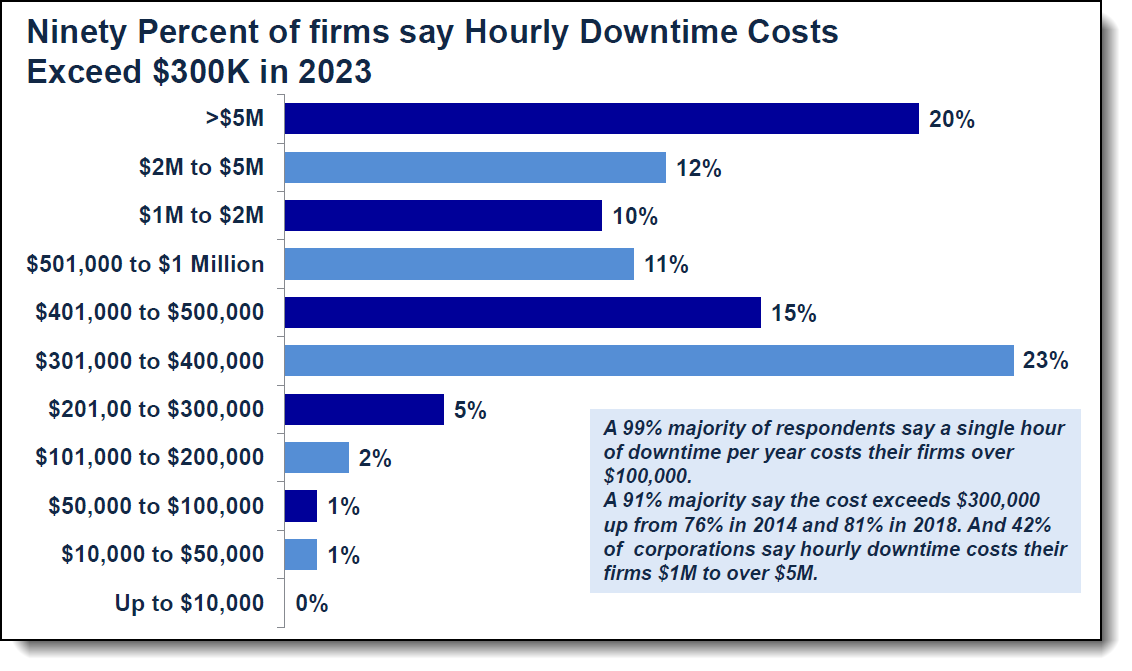
Рисунок 1. Почасовая стоимость простоя ( по результатам глобального исследования надежности серверного оборудования ITIC 2022-2023 и результатов исследования безопасности серверов )
Незапланированные простои аппаратной платформы
По данным ITIC, Lenovo ThinkSystem и IBM лидируют в плане незапланированных простоев .
- Lenovo ThinkSystem: 1,1 минуты
- Cisco UCS: 2 минуты
- Dell PowerEdge: 26 минут
- HPE ProLiant: 39 минут
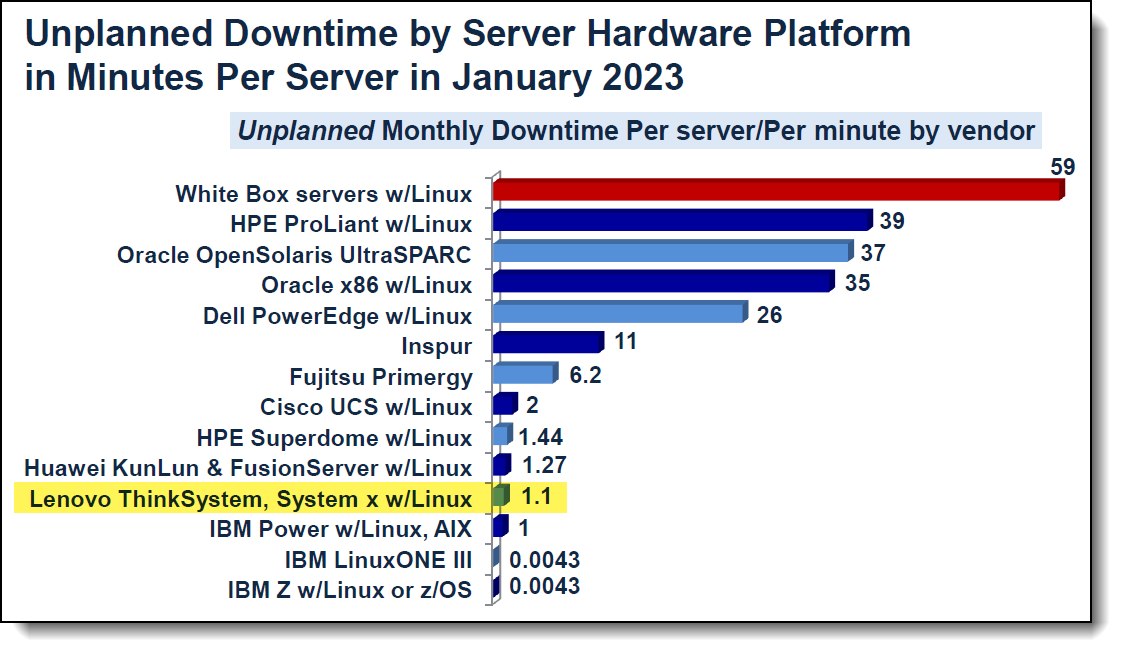
Рис . 2. Незапланированные простои серверной аппаратной платформы в январе 2023 г . ( по результатам глобального исследования надежности серверного оборудования и безопасности серверов ITIC 2022–2023 гг .)
Функции RAS серверов Lenovo ThinkSystem с процессорами Intel Xeon Scalable
В следующей таблице приведен список основных функций RAS масштабируемых процессоров Intel Xeon на серверах Lenovo ThinkSystem.
Табл. 1. Функции RAS серверов Lenovo ThinkSystem с масштабируемыми процессорами Intel Xeon
| Feature |
Category |
2nd Gen Intel (Purley) |
3rd Gen Intel 4S (Cedar Island) |
3rd Gen Intel 2S (Ice Lake) |
4th Gen Intel (Eagle Stream) |
Intel Xeon Max Series (EGS HBM) |
Benefit |
Feature Category 2nd Gen Intel (Purley) 3rd Gen Intel 4S (Cedar Island) 3rd Gen Intel 2S (Ice Lake) 4th Gen Intel (Eagle Stream) Intel Xeon Max Series (EGS HBM) Benefit
| Advanced RAS features |
| Viral Mode of error containment |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Enhanced error containment to improve data integrity, complimentary to corrupt data containment mode |
| Local Machine Check (LMCE) based Recovery |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Enhances MCA recovery-Execution path event, and increases the possibility of recovery |
| SDDC +1, Adaptive DDDC (MR) +1 |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Adaptive virtual lockstep delivers up to two DRAM Device corrections. Also supports Single DRAM correction, as well as single bit correction post final DRAM device map out. |
| PCI Express Live Error Recovery |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCI-e root port error containment, and the opportunity to dynamically recover from the error |
| Intel® UPI Dynamic Link width reduction |
Availability |
Yes |
Yes |
Yes |
Yes |
Yes |
Enables interconnect to continue operation in presence of Interconnect link persistent failure |
| Address range/Partial Memory Mirroring |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
OS managed memory mirroring of selective ranges, increases data integrity at efficient cost |
| MCA 2.0 Recovery (as per eMCA gen2 architecture) |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Firmware first model enables a reliable error sourcing capability with the ability to write to the MSR |
| Standard RAS features |
| Advanced Error Detection and Correction (AEDC) |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Enhanced fault coverage within processor cores, and attempt to recover via instruction retry |
| Error Detection and Correction |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Extensive Error detection and correction capability across the silicon, and the interconnects. |
| Corrupt Data containment-Core |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Uncorrectable data explicitly marked and delivered synchronously to the consuming core to assist error containment and increase system reliability |
| Corrupt Data containment-UnCore |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Uncorrectable data explicitly marked and delivered synchronously to the requestor, to assist error containment and increase system reliability |
| SDDC, Adaptive Data Correction (SR) |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Adaptive virtual lockstep delivers single DRAM Device corrections, at bank granularity. Also supports Single DRAM correction. |
| PCIe “Stop and Scream” |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCI-e root port corrupt data containment feature, increases data integrity |
| Memory Mirroring- Intra iMC |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Increase data integrity by creating a redundant/mirrored copy of data in system DRAM |
| DDR4 memory RANK Sparing |
Reliability |
Yes |
Yes |
No |
No |
No |
Reserved/spare DRAM RANKs are utilized to dynamically map out the failing DRAM RANK into the spare Ranks. |
| Predictive Failure Analysis |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Extensive error logs to assist software in predicting failures |
| Failed DIMM Isolation |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Extensive error logs to help software identify the failing DIMM |
| Virtual (soft) Partitioning |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Virtual Machine Monitor ability to make use of hardware recovery , signaling and error logs |
| Error reporting via IOMCA |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Unified error reporting of the IIO logic to the OS |
| Error reporting through MCA 2.0 (eMCA gen2) |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Firmware first model enables a reliable error sourcing capability |
| Error reporting through eMCA gen1 |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Firmware first model enables reliable error sourcing capability |
| PCIe Card Hot Plug NVMe (Add, Remove, Swap) |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Hot add and repalce of NVMe drives |
| PCI Express ECRC |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCI Express End to end CRC checking, increasing system reliability |
| PCIe Corrupt Data Containment (Data Poisoning) |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCIe corrupt data mode of operation, synchronous signaling of the corrupted data along with data, increases system reliability |
| PCIe Link CRC Error Check and Retry |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCIe link CRC error check and retry, system reliability and recovery from transient errors |
| PCIe Link Retraining and Recovery |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
PCIe link retraining and attempted recovery from persistent link transient errors |
| Mem SMBus hang recovery |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Software ability to reset memory SMBus interface to recover from hang condition |
| DDR4 Command/ Address Parity Check and Retry |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
DDR4 Address and command parity check and retry in the event of errors |
| Time-out timer Schemes |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
Hierarchy of transaction time outs to assist system debug and reliable error sourcing. |
| Intel® UPI Link Level Retry |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Intel UPI link's ability to perform CRC check and retry on errors for higher degree of system reliability |
| Intel® UPI Protocol Protection via 16 bit Rolling CRC |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
Detection of transient data errors over Intel UPI interconnects, via 16bit CRC error checking |
| Processor BIST |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
At power up, Processor's built in self test engine performs test on the internal cache structure for and provides the results to the system BIOS |
| Socket disable for FRB |
Availability |
Yes |
Yes |
Yes |
Yes |
Yes |
The capability to selectively disable socket at the boot time, and therefore allowing system to power-on in a failover configuration |
| Core disable for FRB |
Availability |
Yes |
Yes |
Yes |
Yes |
Yes |
The capability to disable failing cores at boot time, map out the failing core |
| Memory disable for FRB |
Availability |
Yes |
Yes |
Yes |
Yes |
Yes |
The capability to disable failing DIMMs at boot time, map out the failing DIMMs |
| Memory demand and patrol Scrubbing |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
DRAM content is scrubbed with the corrected data due to Demand or patrol scrub operation. Scrubbing DRAM location can prevent accumulation of single-bit errors turning it into uncorrected error. |
| DDR Power Up Post Package Repair (PPR) |
Availability |
Yes |
Yes |
Yes |
Yes |
Yes |
The capability will maps out what platform identifies as bad rows with spare rows in DDR DIMMs, and the repair action will be executed duiring memory training phase at system power up. |
| PIROM for System Information Storage |
Serviceability |
Yes |
Yes |
Yes |
Yes |
Yes |
On package Processor Information ROM |
| MCA Recovery-Execution path |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
OS layer assisted recovery from uncorrectable data errors to prevent system reset |
| MCA Recovery-Non execution path |
Reliability |
Yes |
Yes |
Yes |
Yes |
Yes |
OS layer assisted recovery from uncorrectable data errors detected by Patrol scrubber or LLC Explicit Write Back |
| DCU Scrubbing |
Reliability |
No |
No |
Yes |
Yes |
Yes |
Improves system uptime by minimizing the impact due to high energy particle strike (Soft Errors) within core DCU (aka L1D cache) |
| Partial Cache Line Sparing (PCLS) |
Reliability |
No |
No |
Yes |
No |
Yes |
Extend system uptime in case a single bit memory persistent error is detected. It allows mapping out the cache line with failed single bit by using spare capacity available within the IMC |
| PCIe Enhanced Downstream Port Containment (EDPC) |
Reliability |
No |
No |
Yes |
Yes |
Yes |
EDPC is an enhancement to the Downstream Port Containment (DPC) thereby adding Root Port Programmable IO (RPPIO) errors. |
| DCU/IFU Error Handling Enhancement |
Reliability |
No |
No |
Yes |
Yes |
Yes |
Improving MCA Recovery (Execution path) coverage in case CPU core (DCU/IFU) receives multiple back-to-back read data with ‘Poison Error' (aka Poison Storm). |
| Memory Permeant Fault Detection (PFD) |
Reliability |
No |
No |
No |
Yes |
Yes |
Memory controller will use algrithm to detect and report permanent memory fault |
| DDR5 On-die Error Check and Scrub |
Reliability |
No |
No |
No |
Yes |
Yes |
DDR5 has on-die ECC Error Check and Scrub (ECS) mode with an error counting scheme for transparency. The ECS mode allows the DRAM to internally read, correct single bit errors, and write back corrected data bits to the array (scrub errors) while providing transparency to error counts. |
| DDR5 PMIC Error Handling |
Reliability |
No |
No |
No |
Yes |
Yes |
DDR5 has Power Management IC (PMIC) on DIMM, this capability will isolate the DIMM with PMIC error. |
| RAS features for processors with High Bandwidth Memory (HBM) |
| HBM Only mode, 1LM, 2LM |
Availability |
N/A |
N/A |
N/A |
N/A |
Yes |
High Bandwidth Memory (HBM), it supports HBM Only mode (no DDR DIMMs in the system), 1LM mode (1 level memory: HBM acts same as DDR), and 2LM (2 levels memory: HBM acts as cache of DDR). |
| HBM Permeant Fault Detection (PFD) |
Reliability |
N/A |
N/A |
N/A |
N/A |
Yes |
Memory controller will use algrithm to detect and report HBM permanent fault. |
| HBM Command/Address parity check and retry |
Reliability |
N/A |
N/A |
N/A |
N/A |
Yes |
Memory controller will retry the transaction and try to recovery at CMD/ADDR parity errors on the CMD/ADDR bus. |
| HBM Power Up PPR |
Availability |
N/A |
N/A |
N/A |
N/A |
Yes |
The capability will maps out what platform identifies as bad rows with spare rows in HBM memory, and the repair action will be executed duiring HBM training phase at system power up. |
| HBM Demand and Patrol Scrub |
Reliability |
N/A |
N/A |
N/A |
N/A |
Yes |
Similar to DDR, HBM DRAM content is scrubbed with the corrected data due to Demand or patrol scrub operation. Scrubbing DRAM location can prevent accumulation of single-bit errors turning it into uncorrected error |
| HBM Memory bank sparing |
Reliability |
N/A |
N/A |
N/A |
N/A |
Yes |
Legacy Bank sparing operation, each pseudo channel of HBM supports spare bank for UEFI to make use of after it detects bank failing on the pseudo channel. |
| HBM Corrected Error Reporting |
Reliability |
N/A |
N/A |
N/A |
N/A |
Yes |
Memory Corrected Error reporting supports per rank corrected error counters with leaky bucket algorithm. |
| HBM Disable/Map out for FRB |
Availability |
N/A |
N/A |
N/A |
N/A |
Yes |
The capability to disable failing HBM at boot time, map out the failing HBM. |
Доп. информация
Для дальнейшего анализа надежности серверов Lenovo см. последний отчет ITIC, доступный по адресу:
ITIC 2022-2023 Результаты глобального исследования надежности серверного оборудования и безопасности серверов:
https://lenovopress.lenovo.com/lp1117-itic-reliability-study
Эта статья — одна из серии статей о серверах ThinkSystem V3:
Об авторе
Рэндалл Лундин (Randall Lundin) — старший менеджер по продуктам в группе инфраструктурных решений Lenovo. Он отвечает за планирование и управление серверами ThinkSystem. Рэндалл также является автором и участником многочисленных публикаций Lenovo Press о продуктах ThinkSystem.
Товарные знаки
Lenovo и логотип Lenovo являются товарными знаками или зарегистрированными товарными знаками Lenovo в США и/или других странах. Текущий список товарных знаков Lenovo доступен в Интернете по адресу https://www.lenovo.com/us/en/legal/copytrade/ .
Следующие термины являются товарными знаками Lenovo в США и/или других странах:
Lenovo®
ThinkSystem®
Следующие термины являются товарными знаками других компаний:
Intel® и Xeon® являются товарными знаками корпорации Intel или ее дочерних компаний.
Другие названия компаний, продуктов или услуг могут быть товарными знаками или знаками обслуживания других лиц.
|
|