|
Дизайн архитектуры Lenovo EveryScale для WEKA Storage
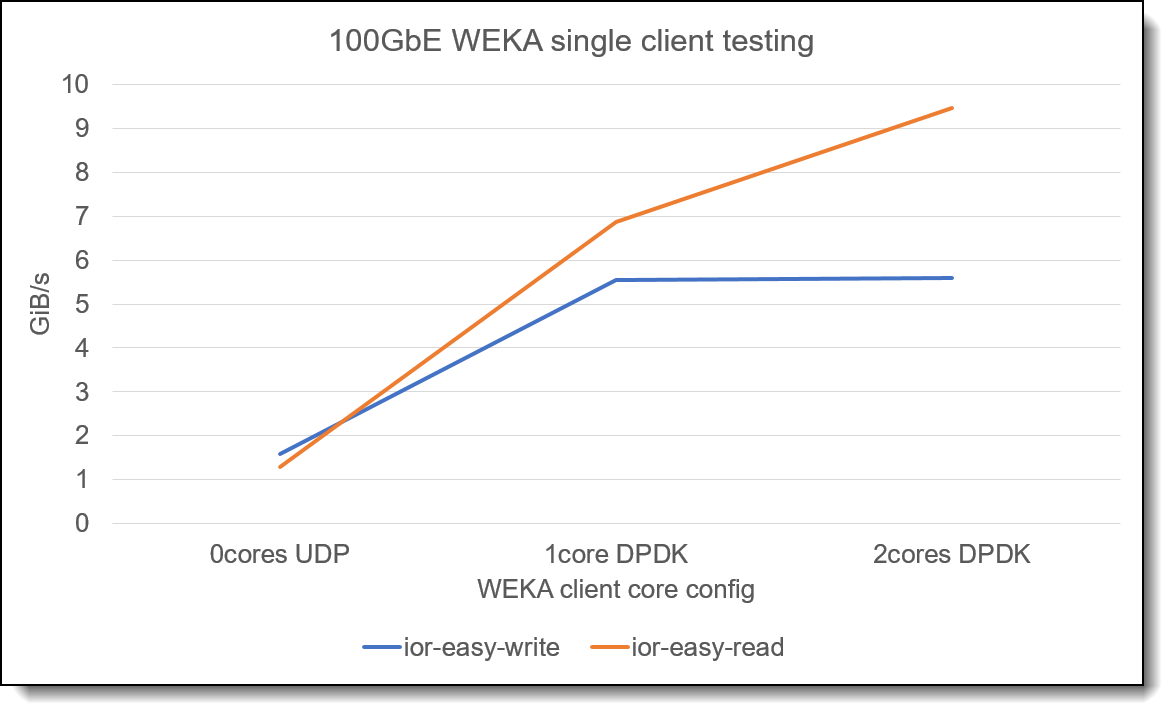
27, февраль 2023 — Авторы : Саймон Томпсон (Simon Thompson) , Стив Эйланд (Steve Eiland Этот технический обзор предназначен для того , чтобы дать представление о возможностях масштабирования и производительности WEKA, а также дать некоторые рекомендации по подходам к настройке параметров кластера и подключения клиентов . WEKA может обеспечить как высокую пропускную способность потоковой передачи , так и высокопроизводительные рабочие нагрузки произвольного ввода - вывода . Как правило , после развертывания системы Lenovo EveryScale WEKA Storage необходимо учитывать очень мало параметров настройки , и с небольшим объемом анализа рабочей нагрузки можно быстро определить оптимальные параметры конфигурации . Для получения дополнительной информации см . краткий обзор решения , Решение Lenovo для высокопроизводительной файловой системы с платформой данных WEKA: https://lenovopress.lenovo.com/lp1691-lenovo-high-performance-file-system-solution-with-weka-data-platform Введение Решение Lenovo High Performance File System Solution с WEKA Data Platform — это программно - определяемое хранилище (SDS , software-defined storage ), которое сочетает в себе ведущие в отрасли серверы Lenovo ThinkSystem с сверхвысокопроизводительной гибридной облачной платформой данных WEKA. Это решение создано для приложений с интенсивным использованием данных , таких как рабочие нагрузки искусственного интеллекта , машинного обучения и высокопроизводительных вычислений , помогая ускорить получение информации и сократить связанные с этим расходы . В этом документе описывается архитектура проектирования , которая поможет техническим группам настроить платформу WEKA для обеспечения наилучшей общей производительности . Современные технологические достижения создали уникальный набор задач для приложений с интенсивным использованием данных , таких как приложения , используемые для искусственного интеллекта (AI), машинного обучения (ML), глубокого обучения (DL) и высокопроизводительных вычислений (HPC) внутри , например , финансовая аналитика , геномика и науки о жизни . Эти сложные приложения требуют максимальной производительности операций ввода - вывода , но устаревшие решения для хранения данных не рассчитаны на масштабирование этих рабочих нагрузок . Платформа данных WEKA® создана специально для решения проблем хранения передовых приложений . WEKA устраняет сложности и компромиссы , связанные с устаревшими системами хранения (DAS, NAS, SAN), и в то же время предоставляет корпоративные функции и преимущества традиционных решений для хранения данных за небольшую часть стоимости . WEKA разработана для удовлетворения строгих требований к хранению рабочих нагрузок с интенсивным использованием данных и ускоряет процесс получения информации из гор данных . Этот технический документ дополняет краткое описание решения Lenovo HPC/AI EveryScale WEKA Storage и содержит подробные сведения о том , как добиться максимальной производительности системы . Заявление об отказе от ответственности : чтобы продемонстрировать некоторые технические соображения , в этом техническом обзоре представлены некоторые данные о производительности . Это не обязательное условие производительности системы хранения Lenovo EveryScale WEKA. Производительность зависит от выбора диска NVMe и конфигурации высокоскоростной сети . Обратитесь к местному техническому представителю Lenovo, чтобы обсудить требования и помочь с прогнозами производительности / требованиями . Конфигурация монтирования клиента WEKA имеет очень мало параметров настройки , чтобы изменить способ ее работы , обычно небольшое количество доступных параметров настройки включается с помощью параметров монтирования при монтировании файловой системы на клиентском узле WEKA. Наиболее важные варианты монтажа , которые следует учитывать , связаны с количеством ядер , выделенных для клиента WEKA. Эти ядра используются при использовании режима DPDK и обеспечивают максимальную производительность для клиентской системы . На следующем графике показано влияние конфигурации подключенного клиента 100GbE с использованием 0, 1 или 2 выделенных ядер . Аналогичное поведение ( хотя и с более высокой производительностью ) можно увидеть при использовании сетей 200GbE или HDR InfiniBand.
Рис . 1. Влияние выделенных ядер на производительность одного узла Из этого графика видно , что использование выделенных клиентских ядер повышает производительность клиента WEKA. Выбор 1 или 2 выделенных ядер будет зависеть от пропускной способности клиентской сети и требований к вводу - выводу рабочей нагрузки клиента . Как правило , 2 клиентских ядра дают хороший выбор После того , как ядра выделены для клиента WEKA, они недоступны для использования в вычислительных приложениях , работающих в клиентской системе . Однако , учитывая , что в современных высокопроизводительных системах обычно используются ЦП с большим числом ядер , потребность в выделении ядер для производительности ввода - вывода вряд ли станет проблемой в целом . При использовании клиента WEKA со SLURM в качестве планировщика HPC необходимо сообщить SLURM, что эти ядра больше не доступны для вычислительной работы на клиенте . Следующие параметры конфигурации для установки основной специализации SLURM должны использоваться в файле slurm.conf:
Параметр TaskPluginParam=SlrumdOffSpec указывает SLURM, что процесс - демон запускается вне специализированных ядер , использование AllowSpecResourcesUsage позволяет пользователям планировщика использовать конфигурацию ядра в своем клиентском сценарии задания . Следующая строка используется для сценария задания при отправке задания в кластер SLURM:
Эта строка указывает SLURM, что на вычислительном узле требуются два специализированных ядра , и запрещает подключение этих ядер к CGROUP для выполнения вычислительного задания или их использование для процессов slurmd. Внутри SLURM использует механизм нумерации ядер , отличный от вывода lscpu, однако по умолчанию сначала будет назначено ядро с наибольшим номером на CPU1, а затем ядро с наибольшим номером на CPU0. Чтобы обеспечить согласованность между различными типами узлов , важно убедиться , что клиентское крепление WEKA использует эти номера ядер . Пример bash- скрипта для определения используемых ядер :
Этот пример сценария определяет самые высокие номера ядер от CPU0 и CPU1 в системе с двумя сокетами , эти номера ядер затем используются для монтирования системы хранения WEKA, например :
Наконец , при использовании специализированных ядер с WEKA и SLURM необходимо внести изменение в файл конфигурации клиента WEKA (/etc/wekaio/weka.conf), изменив значение isolate_cpusets на false. Как только это будет сделано , weka-agent следует перезапустить с помощью команды systemctl restart weka-agent. В качестве дополнительной опции монтирования , которая может быть уместна в некоторых средах , используется «forcedirect». По умолчанию клиентское программное обеспечение WEKA использует некоторое кэширование , а опция forcedirect отключает такое кэширование . Это может привести к повышению пропускной способности данных , но может привести к некоторому влиянию на небольшие операции ввода - вывода или операции с метаданными . При использовании WEKA в новой среде следует использовать оценку производительности как с параметром forcedirect, так и без него , чтобы определить наилучшую конфигурацию для среды . Многим пользователям HPC рекомендуется использовать опцию монтирования клиента forcedirect. Сетевая конфигурацияПрограммное обеспечение WEKA может использовать несколько сетевых адаптеров на сервере с максимальной производительностью , наблюдаемой при использовании адаптеров с поддержкой RDMA. В решении Lenovo EveryScale WEKA Storage рекомендуются адаптеры NVIDIA Networking VPI. Эти устройства поддерживаются WEKA, а также рекомендуются для использования в клиентских системах , обращающихся к системе хранения . При монтировании системы хранения важно , чтобы имя адаптера с поддержкой RDMA было передано в параметры монтирования клиента WEKA. Точно так же адаптеры должны быть подключены к контейнерам WEKA, работающим на серверах хранения . В настоящее время WEKA поддерживает не более 2 адаптеров RDMA на серверах хранения . Для максимальной производительности при использовании с сервером Lenovo ThinkSystem SR630 V2 их следует размещать в слотах 1 и 3. Это гарантирует , что один адаптер подключен к каждому домену NUMA в пределах сервер . Если с WEKA используется серверная часть объекта или требуется многопротокольный доступ ( например , NFS, SMB или Object), можно использовать третий адаптер , установленный в слоте 2, для обеспечения выделенного сетевого подключения для этих служб . Производительность хранилищаС кластером из шести узлов , использующим Lenovo ThinkSystem SR630 V2 и использующим HDR InfiniBand в качестве межсоединения , можно ожидать , что производительность достигнет 5,1 миллиона операций ввода - вывода в секунду при чтении и до 228 ГБ / с производительности при потоковом чтении . Темы в этом разделе :
Настройки прошивки UEFI Для достижения максимальной производительности WEKA на сервере Lenovo ThinkSystem SR630 V2 может потребоваться настроить некоторые параметры UEFI. Измените режим работы системы на « Максимальная производительность », а затем перезагрузите систему . Режим работы — это макрос UEFI, который автоматически изменяет несколько параметров для обеспечения максимальной производительности . При использовании инструмента Lenovo OneCLI для изменения настроек UEFI установите :
Очень важно , чтобы система была перезагружена после изменения режима работы , прежде чем приступать к изменению других настроек микропрограммы . После изменения режима работы и перезагрузки системы необходимо также изменить следующие параметры UEFI:
Параметры загрузки ядра Для лучшей производительности в системе Lenovo ThinkSystem SR630 V2 рекомендуется установить следующие параметры ядра во время загрузки :
Их можно установить с помощью инструмента grubby, например :
Также необходимо создать следующий файл конфигурации , чтобы изменить поведение драйвера i2c и предотвратить проблемы с WEKA при доступе к дискам NVMe с помощью SPDK. /etc/modprobe.d/i2c_i801.conf:
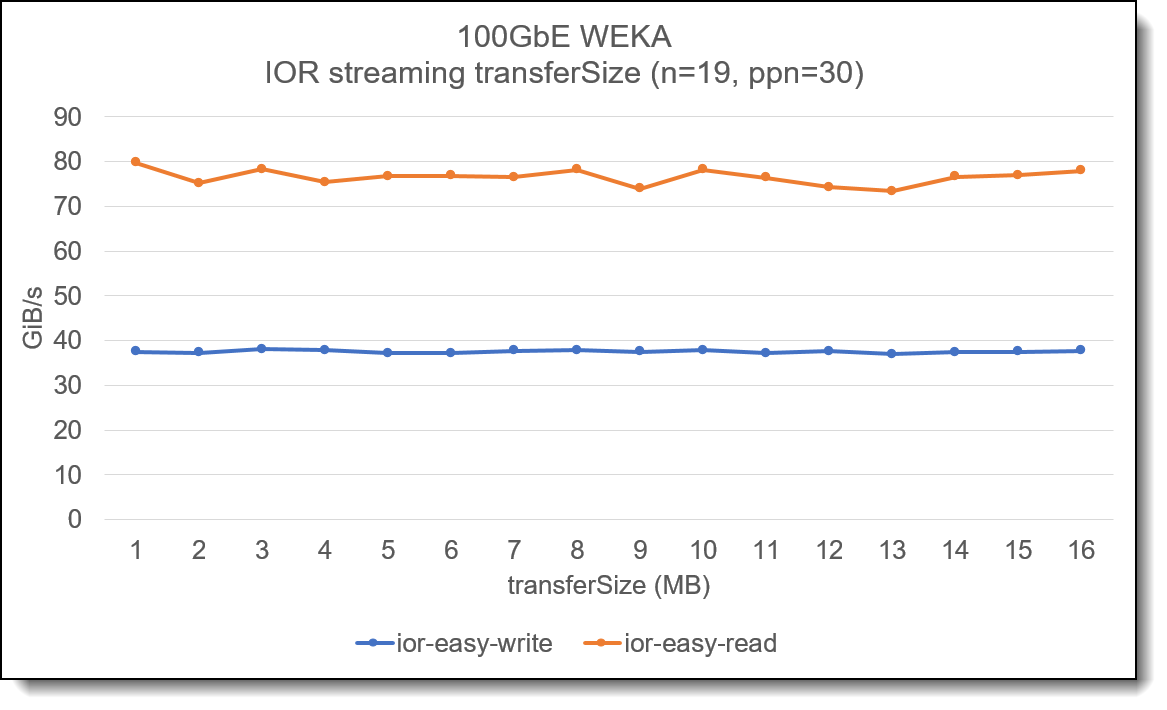
После установки сервер должен быть перезагружен , чтобы изменения вступили в силу . Конфигурация сервера WEKA Сервер Lenovo ThinkSystem SR630 V2 представляет собой двухпроцессорную платформу . Разработка производительности в Центре инноваций Lenovo HPC показала , что производительность можно значительно повысить , используя многоконтейнерные серверные части с WEKA. В этой конфигурации на сервер развернуто два контейнера WEKA, каждому из которых выделено 15 ядер . При распределении дисков NVMe в Lenovo ThinkSystem SR630 V2 важно , чтобы идентификаторы ядер сопоставлялись с контейнером , а диски , подключенные к узлу NUMA, также сопоставлялись с этими ядрами . Если используется конфигурация с одним контейнером или не учитывается распределение ядер и дисков , маловероятно , что можно будет достичь максимальной производительности системы . Профессиональные услуги Lenovo доступны для развертывания и настройки системы хранения Lenovo EveryScale WEKA. Настройка выделения ядер для интерфейсных и вычислительных ядер требует тщательного рассмотрения , поскольку выбор этих значений влияет на производительность метаданных и многопротокольного доступа , а точная конфигурация будет зависеть от развертывания клиента . Объем потоковой передачи данных Во многих файловых системах HPC важно учитывать концепцию размера блока , и потоковые операции ввода - вывода должны быть согласованы , чтобы передача данных соответствовала размеру блока файловой системы . В WEKA отсутствует понятие размера блока файловой системы , а влияние использования различных размеров передачи ввода - вывода для потоковой передачи данных незначительно . На следующем графике показан анализ с использованием эталонного инструмента IOR и показано влияние изменения размера передачи при выполнении нескольких потоков на нескольких клиентских узлах :
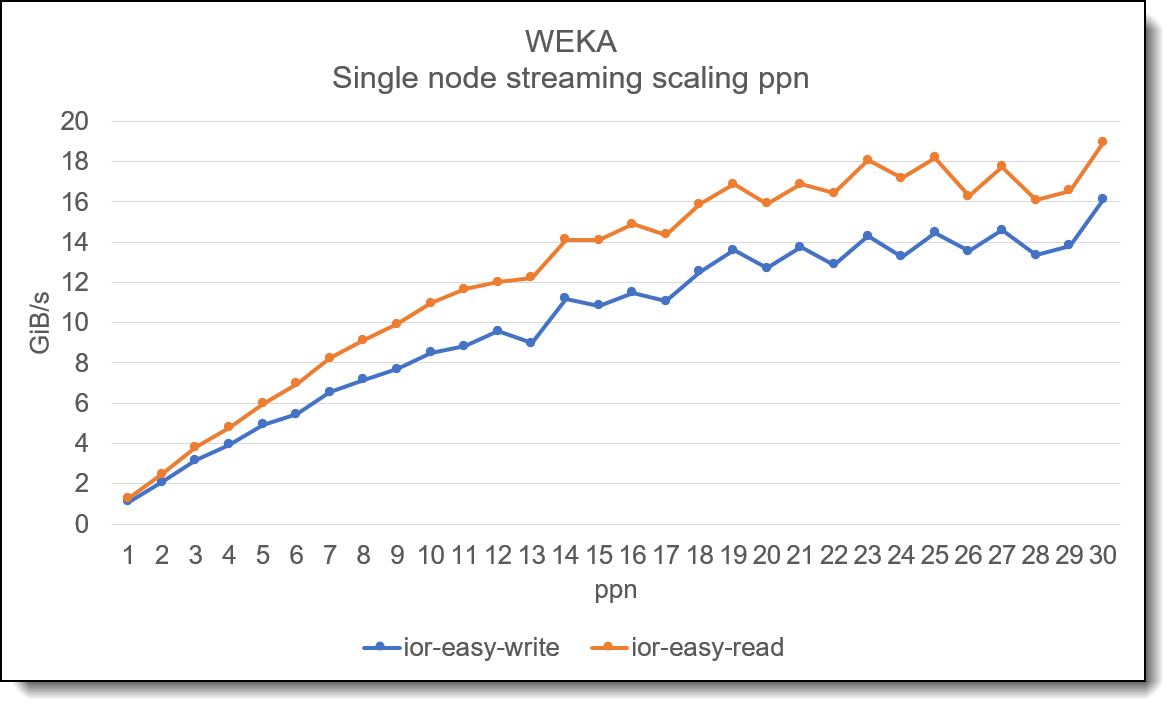
Рис . 2. Влияние изменения размера передачи на потоковый ввод - вывод Примечание . Этот график не предназначен для демонстрации максимальной производительности системы , но используется для демонстрации влияния изменения размера передачи / ввода - выводов при выполнении потокового чтения или записи в решении Lenovo EveryScale WEKA Storage. Производительность потоковой передачи одного узлаКак и во многих параллельных файловых системах , для достижения максимальной производительности одного клиента необходимо увеличить количество потоков в клиентской системе , прежде чем будет достигнута максимальная производительность .
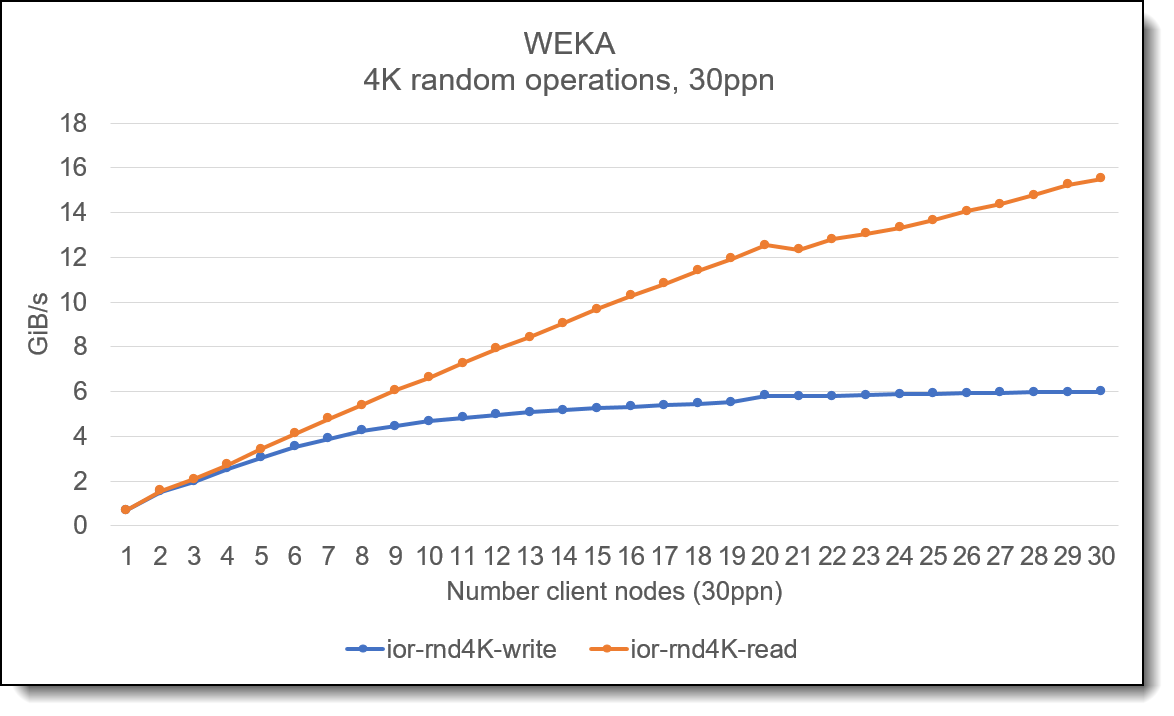
Рисунок 3. Масштабирование производительности одного узла с увеличением количества потоков На приведенном выше графике показано , как будет масштабироваться увеличение количества потоков при использовании IOR на одном клиенте . В приведенных выше тестах для демонстрации общего масштабирования используется одна итерация IOR. При использовании нескольких итераций линия , скорее всего , будет выглядеть менее « ухабистой ». В дополнение к высокой производительности потоковой передачи данных , WEKA также обеспечивает отличную производительность случайного 4K.
Рис . 4. Случайные операции ввода - вывода 4K На приведенном выше графике показана производительность системы хранения при увеличении количества клиентских узлов , при этом на каждом узле выполняется 30 потоков . График показывает , что операции произвольного чтения 4K хорошо масштабируются по мере увеличения количества клиентских узлов . Хотя на графике показана совокупная случайная пропускная способность 4K, обычно это тест на привязку «IOPS», который показывает , что WEKA способна обеспечить высокую производительность IOPS. АвторыСаймон Томпсон (Simon Thompson) — старший менеджер подразделения HPC Storage & Performance и возглавляет группу HPC Performance and Benchmarking в группе WW Lenovo HPC. До прихода в Lenovo Саймон посвятил 20 лет разработке и поставке исследовательских вычислительных технологий . Стив Эйланд (Steve Eiland) — глобальный менеджер продуктов HPC/AI Storage, отвечающий за интеграцию всех продуктов хранения для сообщества HPC/AI Lenovo. Он сосредоточен на работе с вертикальными рынками хранения данных и предоставлении передовых решений для хранения данных с максимальной производительностью в рамках глобальной команды Lenovo HPC. До прихода в Lenovo Стив работал в различных компаниях , связанных с технологиями , в качестве инженера по эксплуатации , инженера по продажам и менеджера по развитию бизнеса , поддерживая продукты в области хранения данных , межсистемных соединений хранения , IPC ( inter processor communication, межпроцессорного взаимодействия ) и вычислений . Товарные знакиLenovo и логотип Lenovo являются товарными знаками или зарегистрированными товарными знаками Lenovo в США и / или других странах . Текущий список товарных знаков Lenovo доступен в Интернете по адресу https://www.lenovo.com/us/en/legal/copytrade/ . Следующие термины являются товарными знаками Lenovo в США и / или других странах : Другие названия компаний , продуктов или услуг могут быть товарными знаками или знаками обслуживания других лиц . |
| |||||||||||||||||